

This section of the K-OAr Center’s site is a porting of some content from the Speech Data & Tech website, formerly at https://speechandtech.eu/ (you can find its latest Internet Archive copy here).
Research Domains
What are the various ways in which disciplines deal with speech data?
The disciplines that work with speech data and that could benefit from utilizing digital technology have widely divergent disciplinary approaches. To better understand what they have in common and how computer scientists can support the research practices or scholars, we offer a short outline of the methodological approaches of a number of disciplines that study language and speech as such, or as carrier of specific meanings.
Oral History
Oral History is a term commonly used in the context of research practices based on the use of spoken word material as a source for historical research. From interviewing eye-witnesses in historical events, to the analysis of interviews as a historical source, to the collecting and archiving of recorded interviews and stories: all stages in the process are associated with the umbrella notion Oral History. This makes the term both hard to define and meaningful in a broad field of historical research.

Oral History is sometimes seen as a relatively new method of historical research in the scope of academic historiography, beginning to rise in the mid-20th century. Important in the shift towards the use of oral sources are advancements in portable recording technology, combined with a new interest in on (i) the personal experience of historical events, and (ii) the common man’s story within history research.
With the Digital Age coming in full swing at the start of 21st century, Oral History has begun to experience a paradigm shift. The internet is becoming an important place for oral history archives, making sources more publicly available. Digital tools are more and more adopted within the field, bringing previously tedious or even impossible research steps only mouse-clicks away. Mobile phones are making the recording of oral history available for virtually anyone interested. These developments have given the oral historian great expectations and new possibilities, but also received strong criticism, and the doubts and possible pitfalls associated with the digitalisation of the Oral History landscape have a crucially impact on the appreciation of what is technologically feasible.
The main goal of this website is to give an overview of technology that can be used in the processing of Oral History resources and interview data in general: from an analogue tape and perhaps a handwritten summary to a digital recording including digital transcripts, speaker allocation/recognition (who is speaking when), emotion-markers, speech velocity and much more.
Computational Linguistics
Natural Language processing and Text Mining
While ‘Text Analytics’ is a more generic term, more specific terms that are current in computer science and linguistics are ‘Natural Language Processing’ and ‘Text Mining’. NLP or Natural Languages Processing is the umbrella term for the processing, exploration and analysis of data using computational linguistic tools and approaches. ‘Text mining’ is the process of converting unstructured or semi-structured oral and written data into structured data for exploration, analysis, and interpretation. Other methodologies involve statistical tools and machine learning. The scheme below illustrates the variety of focuses when applying computational methods to text.
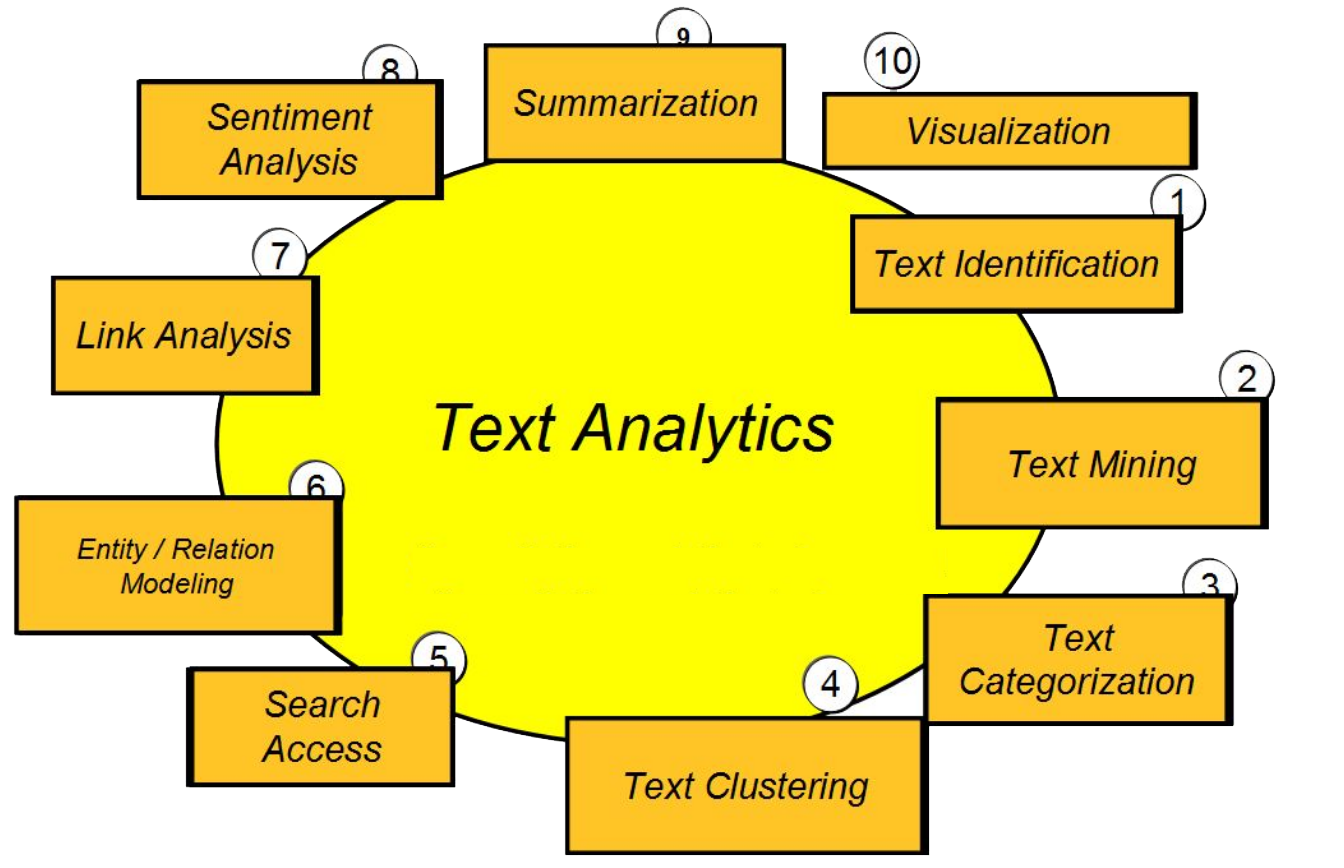
NLP tools that are commonly used to facilitate text processing and information extraction are spell checkers/correctors, tokenizers, stop word removers, stemmers, lemmatizers, POS-taggers, chunkers such as sentence splitters, syntactic parsers, thesauri and ontologies, keyword extractors.
Automated speech recognition (ASR) tools partially replace manual transcription. They can mark silences and recognize different speakers in, for example, an interview. An important surplus is that ASR converts spoken language into text which can be aligned with the spoken fragments. Emotion recognition detects positive and negative feelings, taking into account silences, tone/pitch and role-taking.
Named entity recognizers (NER) extract named entities, i.e. proper nouns such as person names, names of organisations, geographical terms, but also dates, percentage, numbers.
Other Information extraction (IE) tools detect keywords, generate frequency lists and summaries, produce word clouds, and categorise documents. There are also excellent tools for discovering (unexpected) patterns such as concordances (KWiC/Keywords in Context) and correlations.
It speaks for itself that this technology has been developed with a strong focus on the characteristics of language expressed in written form. But now that technologies are increasingly capable of automatically turning speech into text, the next challenge will be to develop specific methodologies for the automatic analysis of spoken text. This is at the core of the discipline of language technology, but is still unexplored territory with regard to typical humanities data such as oral history interviews, or data that is used by media scholars such as television and radio broadcastings.
Sociolinguistics
Sociolinguistics means investigating the relationships between language and society and inspecting the various functions of language in society. Language and society are related in many ways:
- social structure may influence/determine linguistic structure and linguistic behaviour (language varies according place of origin, age, social class, style, medium, gender…);
- linguistic structure and behaviour may influence/determine social structure (a particular accent may convey a particular social or ethnic identity).
Sociolinguistics allows us to better understand the structure of language and how languages function in communication.
Sociolinguistics is oriented toward both data and theory: any conclusion a sociolinguistic draws must be solidly based on evidence. If a sociolinguist seeks to investigate the possible relationships between language and society must ask good questions, first, and then must find the right kinds of data that bear on those questions.
Since sociolinguistics is of necessity an empirical science, it has to be founded on adequate databases. Oral archives might be exactly one of the most relevant databases used in the research, allowing for socio-phonetics investigations and historical sociolinguistic analysis (under the ‘real-time’ paradigm).
Language and Speech Technology
‘Language and Speech Technology’ is about developing computational methods for processing spoken language. In spoken language, a physical signal – minute changes of air pressure – carries information – speech sounds, words, emotions, identity.
Automatic Speech Recognition (ASR), Text-to-Speech (TTS) and Dialog Systems (DS) are the three main research areas, and they are complemented by Speaker Diarisation, Voice Activity Detection, Emotion Recognition, and Segmentation.
Automatic Speech Recognition
 In ASR, the words of an utterance are extracted. Statistical methods, and, more recently, neural networks have shown to be very successful. These systems are trained on large speech corpora which consist of the raw audio files and their verbatim transcripts. ASR systems achieve the best results for speech similar to the material they were trained with. Depending on the application area, the raw output of speech recognition systems needs further processing, e.g. text normalisation and punctuation.
In ASR, the words of an utterance are extracted. Statistical methods, and, more recently, neural networks have shown to be very successful. These systems are trained on large speech corpora which consist of the raw audio files and their verbatim transcripts. ASR systems achieve the best results for speech similar to the material they were trained with. Depending on the application area, the raw output of speech recognition systems needs further processing, e.g. text normalisation and punctuation.
Text-to-Speech
TTS (or Speech Synthesis) aims to generate an audio signal from a given text or concept. There are two main approaches: parametric synthesis, which generates an audio signal from a mathematical description of the articulation process, and unit-selection which generates an utterance by concatenating small building blocks of prerecorded speech. Recent research on TTS also explores the use of neural networks to improve the perceived quality of the speech output.
Dialog Systems
In DS research, the focus is on high-quality speech communication between humans and machine systems. Typical examples are information, assistance or education systems, sales and entertainment, but also support systems for hands-free operation. The major challenge in this field is the smooth interaction of multimodal communication, namely speech, text, graphics and haptics.
Speaker Diarisation
Speaker Diarisation is the process of assigning speakers to fragments of a given speech signal. Humans are very good at this, but more research is needed for machines to reach useful performance. The same is true for voice activity detection: here, the challenge is to first determine non-speech parts of the signal, and then to decide about their communicative function.
Emotion Recognition
In Emotion Recognition, biophysical features are traced in the speech signal and mapped to emotional states. Such features are, among others, intonation contours, speech rate and variation. Again, the main challenge is to identify which speech features can be mapped to emotional states in which contexts.
Segmentation
Finally, in segmentation, fragments of the speech signal are associated with some symbolic data. In phoneme-based segmentation systems, a raw verbatim transcript is converted to a sequence of phonemes which are then mapped to the speech signal. The challenges here are languages with segmentation features not covered by the training data, e.g. tone languages, or languages for which there exists very little training material.
Interdisciplinarity
Language and Speech Technology is interdisciplinary research. Advances in LST will benefit diverse scientific areas, and vice-versa the contributions of other research fields are needed to advance LST. The relationship between signal and information is complex and multi-dimensional, and disambiguation may require access to knowledge about the context in which the signal was produced and perceived.
For example, based on the acoustic signal alone, an automatic speech recognition system may return the same probability for the word sequences “kind of research that I can duct” and “kind of research that I conduct”. A syntactic analysis supports the second word sequence, because a verb is highly probable at this position, and this is further supported by a lexical context analysis showing that ‘research’ and ‘conduct’ co-occur very often.